
Python es de facto el lenguaje de programación más popular del momento. Pero, ¿cómo realizar tareas sencillas en paralelo y sin apenas esfuerzo?
Lo creas o no, esto es es posible y lo mejor es que sólo existen tres palabras claves que necesitas conocer: numba, map y submit
numba
No nos engañemos, programar en paralelo va a añadir inevitablemente mayor complejidad al código y pronto aprenderás que existe algo llamado Heisenbugs.
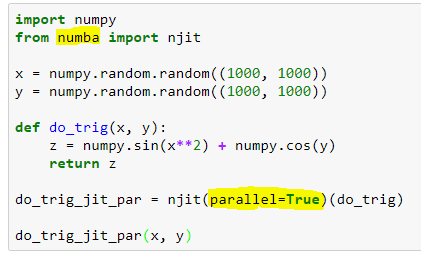
Por lo tanto y en primer lugar, si lo que queremos es acelerar el código, con numba conseguiremos dos ordenes de magnitud de mejora simplemente añadiendo ´@jit´ a una función.
Pero, si sigues leyendo esto es porque quieres programar en paralelo, sin apenas esfuerzo y ya tienes:
- perfilado tú código para ver dónde se encuentran los cuellos de botella
- pensado en la complejidad de tus algoritmos y/o utilizado la herramienta adecuada de la forma adecuada (ej. consejos de NumPy y pandas).
- testeado la función en secuencial
Entonces… ¡buenas noticias! Con la nueva versión de numba también podemos paralelizar las funciones compiladas al vuelo:
map & submit
Cualquier librería para trabajar en paralelo tendrá implementadas estás dos funciones:
- map: Si tienes una operación que debe repetirse n veces de forma indpendiente y en paralelo

- submit: Si la tarea a repetir depende de alguna condición y no ves claro cómo usar map

Ambas operaciones pueden llevarse a cabo trabajando con dos técnicas muy diferentes:
- multithreading: compartimos datos en memoria y trabajamos de forma independiente sobre ellos (ej. leer archivos de una lista de nombres).
- multiprocessing: nuestros datos de entrada pueden cambiar durante la operación por lo que necesitamos hacer una copia de cada uno de ellos y distribuirlo de forma independiente.

Por defecto, el intérprete de Python bloquea las variables globales y, por tanto, si queremos trabajar sobre ellas necesitamos copiar datos de un lado a otro (lo que conlleva un tiempo extra y obliga a usar multiprocessing). Esto se le conoce como GIL y es un tema de gran controversia.
Entonces, ¿por dónde empiezo y qué herramienta es la mejor?
Nosotros recomendamos seguir estos tres tutoriales de la conferencia SciPy 2017.
Parallel Data Analysis in Python
- Para aprender los fundamentos y varias opciones que existen dentro de Python.
Parallelizing Scientific Python with Dask
- Si trabajas con NumPy/pandas y quieres paralelizar o trabajar con archivos que no caben en memoria
Numba: Tell Those C++ Bullies to Get Lost (2017)
- Si inevitablemente tienes muchos bucles for y NumPy no es suficiente
Conclusiones (TL;DR)
Si de verdad necesitas trabajar en paralelo, usa Dask (ver diapositivas).